داده کاوی با پایتون : دیتاماینینگ با پایتون
دادهکاوی فرایند کشف اطلاعات پیشبینی شده از تجزیه و تحلیل پایگاه دادههای بزرگ می باشد. هدف مورد نظر از دادهکاوی ،ایجاد یک مدل از یک مجموعه داده است به طوری که بتوان بینش خود را به مجموعه دادههای مشابه تعمیم داد.
داده کاوی با پایتون
نرمافزار برنامهنویسی پایتون یکی از نرمافزارهای کارآمد در دادهکاوی میباشد. پایتون به دلیل سادگی و همه منظوره بودن و ایجاد برنامههای کاربردی و تحلیل داده مورد توجه همگان قرار گرفته است. همچنین داشتن کتابخانههای متعدد و دسترسی آسان به آن موجب گرایش بسیاری از برنامه نویسان به زبان پایتون شدهاست. به همین دلیل به توضیح نکاتی از تکنیکهای دادهکاوی با پایتون میپردازیم.
کتابخانههای لازم برای داده کاوی با پایتون
برای انجام داده کاوی با پایتون باید کتابخانههای لازم را بدانیم تا با بهرهگیری از آنها کدها را اجرا کنیم. در ادامه دستهای از کتابخانههای مهم را نام میبریم.
- Numpy: ماژولی توسعه یافته و متن باز است که عملکردهای از پیش تعیین شدهای از روتینهای عددی در اختیار ما قرار میدهد.
- Scipy: این امکان را به ما میدهد که در ارایههای n بعدی دست ببریم.
- Matplotlib: برای ما تصویر سازی و ترسیم و ویژوالیزیشن را ممکن میکند.
- Matplotlib: بیشتر برای الگوریتمهای معروف یادگیری ماشین است.
- Pandas: دارای ساختارهای اطلاعاتی سطح بالا و ابزارهای طراحی برای عملیات ساده و سریه آنالیزی است.
دیگر کتابخانه های مورد نیاز: Theono ,NLTK ,statsmodels ,gensim, …
فراخوانی کتابخانه در پایتون
برای استفاده از کتابخانهها پیش از شروع کدنویسی باید آنها را فراخواند:
|
1 2 3 4 5 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np import scipy.stats as stats import seaborn as sns |
آمادهسازی داده با پایتون
اولین قدم در داده کاوی آمادهسازی داده ها می باشد که روشهای مختلفی با استفاده از کتابخانههای متفاوت (بسته به نوع دادهها و نتیجه مورد نیاز) دارد. آمادهسازی داده برای الگوریتمهای معروف یادگیری ماشین(machine learning) که یکی از ابزارهای داده کاوی در پایتون محسوب میشود نیز کاربرد دارد:
- تحلیل دادهها
- مدیریت دادههای ناکامل
- نرمال ساختن دادهها
- دستهبندی دادهها
یکی از روشهای معرفی داده به برنامه در پایتون از طریق دستور زیر است (مثال: دیتاست IRIS را در نظر میگیریم که شامل دادههای مرتبط با ۵۰ نمونه از ۳ مدل گل میباشد. دادههای دریافتی شامل ۵ ردیف میباشند ۴ ردیف اول مقادیر و ردیف آخر کلاس نمونه ما میباشد):
با استفاده از کد زیر میتوانیم دیتاست IRIS را در پایتون لود کرده و آماده سازی کنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import urllib2 url = 'http://aima.cs.berkeley.edu/data/iris.csv' u = urllib2.urlopen(url) localFile = open('iris.csv', 'w') localFile.write(u.read()) numpy import genfromtxt, zeros # read the first 4 columns data = genfromtxt('iris.csv',delimiter=',',usecols=(0,1,2,3)) # read the fifth column target = genfromtxt('iris.csv',delimiter=',',usecols=(4),dtype=str) print set(target) # build a collection of unique elements set(['setosa', 'versicolor', 'virginica']) |
با استفاده از کدهای فوق ما دیتاست iris را دانلود میکنیم و در یک فایل بنام iris.csv ذخیره میکنیم و سپس فایل iris.csv را با استفاده از کتابخانه genformtxt لود میکنیم
تصویر سازی داده ها در پایتون
فهمیدن این که دادهها چه اطلاعاتی به ما میدهند و چگونگی ساختار آنها یک مأموریت مهم در دادهکاوی میباشد. تصویر سازی به ما کمک میکند تا به صورت گرافیکی این اطلاعات را بدست آوریم. استفاده از دستورهای نمودار کشیدن به ما کمک میکند تا مقدارهای دو داده مختلف را به صورت گرافیکی با هم مقایسه کنیم.
مثال:دستور زیر دیتای Iris را برای ما نمایش میدهد (البته ما تنها دو ستون اول را نمایش میدهیم)
|
1 2 3 4 5 |
import plot, show plot(data[target== 'setosa',0],data[target =='setosa',2],'bo') plot(data[target== 'versicolor',0],data[target =='versicolor',2],'ro') plot(data[target== 'virginica',0],data[target =='virginica',2],'go') show() |
نتیجه دستورات فوق نموداری به شکل زیر می باشد:
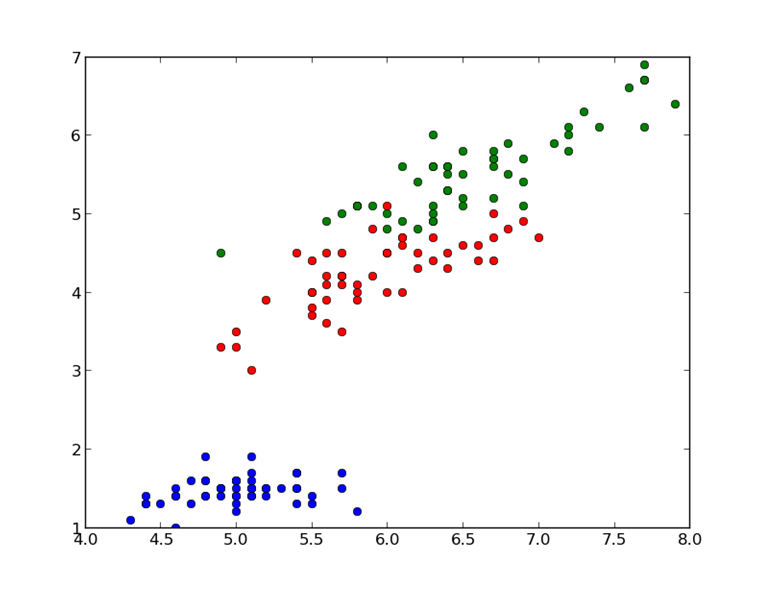
نمایش دیتای Iris در پایتون
گراف حاصل شامل ۱۵۰ نقطه و ۳ رنگ که نشانگر کلاسها هستند است.
با استفاده از کتابخانه plot و show در پایتون میتوانیم نمودارهای گرافیگی خود را همانند تصویر فوق ترسیم کنیم.
بعد از آماده سازی داده ها ، در داده کاوی معمولا ما به دنبال یکی از اهداف زیر می باشیم:
- خوشه بندی داده ها
- طبقه بندی داده ها
- رگرسیون روی داده ها
- و ….
در ادامه مختصری در خصوص موارد فوق توضیح میدهیم تا با مفاهیم فوق کمی آشنا شوید:
طبقهبندی(classification) یا دسته بندی:
هدف از طبقه بندی داده ها این است که با استفاده از داده های موجود یک مدل را بسازیم که بتوانیم با این مدل کلاس داده های آینده را پیش بینی کنیم یا بعبارت دیگر ابتدا دادهها را ردهبندی میکند برای اینکه مدلی ساخته شود که بتوان از آن برای پیش بینی رده آنهایی که مشخص نیستند استفاده کرد.
بعنوان مثال طبقهبندی ایمیل بعنوان اسپم یا قانونی
خوشهبندی(clustering)
خوشه بندی یک فرایند اتوماتیک است که دادهها را به مجموعه و دستههایی که اعضای آنها مشابه هم می باشند تقسیم میکند. در هر دسته اعضا با هم مشابهاند و با دستههای دیگر نامشابه می باشند.
در کنار خوشهبندی مفهوم دستهبندی وجود دارد. هدف خوشهبندی پیدا کردن دسته شمارا و متناهی از خوشههاست برای توصیف داده هاست اما دستهبندی هدف ایجاد یک مدل پیشگویی کننده را دارد که هم توانایی دستهبندی دادههای ورودی را داشته باشد و هم بتوان از آن برای پیش گویی اینکه داده تازهوارد شده متعلق به کدام دسته است استفاده کرد.
رگرسیون(Regression)
این الگوریتم به بررسی روابط میان دادهها و مدل سازی آنها میپردازد. هدف این تکنیک پیش بینی مقدار یک متغیر پیوسته بر اساس مقادیر دیگر متغیرهاست. شامل دونوع است:
- رگرسیون خطی
- رگرسیون غیر خطی
کد های زیر یک مثال برای رگرسیون خطی در پایتون می باشد:
|
1 2 3 4 5 6 |
from numpy.random import rand x = rand(40,1) # explanatory variable y = x*x*x+rand(40,1)/5 # depentend variable from sklearn.linear_model import LinearRegression linreg = LinearRegression() linreg.fit(x,y) |
جهت رسم نمودار نیز کد زیر مورد استفاده است:
|
1 2 3 4 5 6 |
from numpy import linspace, matrix xx = linspace(0,1,40) plot(x,y,'o',xx,linreg.predict(matrix(xx).T),'--r') show() [/php] |
نتیجه کد بدین صورت است:
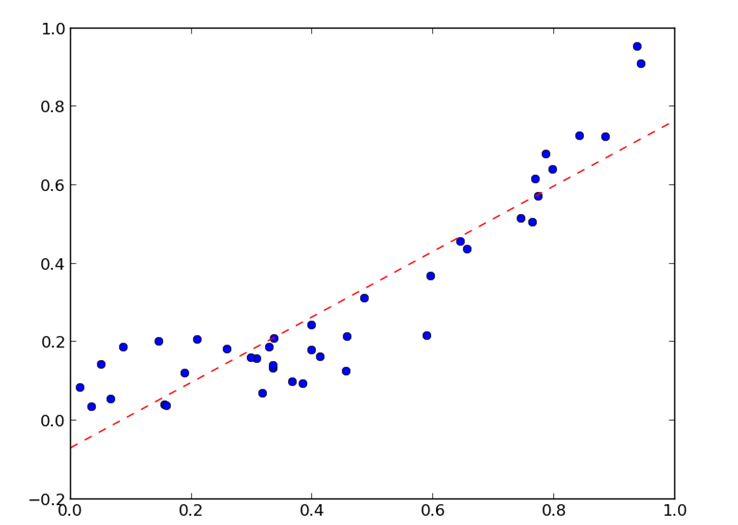
رگرسیون خطی در پایتون





اجازه هست این مطلب رو به اشتراک بزارم؟
فرهنگ خوبیه که مطالب خوب رو به اشتراک بزاریم